Towards developing future-ready skills with generative AI
April 13, 2026
Gal Elidan, Research Scientist, and Yael Haramaty, Senior Product Manager, Google Research
Our new research demonstrates a novel approach to assess “future-ready” skills using GenAI. The results of our study with New York University found the AI scoring to be on par with human experts. This research experiment, Vantage, is now available on Google Labs.
Quick links
As AI evolves at an unprecedented pace, there is a renewed focus on "future-ready" skills — the durable human competencies that will remain valuable regardless of technological shifts or automation. International frameworks, such as the OECD Learning Compass 2030 and the WEF’s Future of jobs report, have identified a set of priority skills, both highlighting the same core competencies, including critical thinking, collaboration, and creative thinking. While these skills have been considered essential long before the rise of AI, they are now becoming more critical than ever.
Today we are sharing Vantage, a research experiment for assessing future-ready skills by leveraging generative AI to create conversations in simulated environments. Developed in partnership with pedagogy experts and researchers from New York University, Vantage is designed to offer high school and college students a sandbox environment for practice and validated assessment, built with the same systematic methodology traditionally used for core academic subjects, such as math or science. Vantage is now available in English for sign up on Google Labs.
Measuring what's difficult to measure
At the heart of any effective learning process is feedback and assessment, both essential for individual growth and effective teaching. In global education systems, it is often the case that what is measured is what is taught.
Future-ready skills, however, are notoriously hard to measure. Typical tests are too rigid to capture people's thought processes and interactions and they are far removed from how these skills are used in the real world. While testing these skills in real human interactions would be ideal, it is also too resource-intensive and hard to standardize and grade consistently across many students. For instance, how would you fairly assess conflict resolution if a group never disagrees, or the ability to build creatively upon each other's ideas if they settle on the first one that comes up?
Our research team set out to discover how to assess students’ future-ready skills using a scalable, validated approach that could empower educators to align lessons with these skills and support student growth.
Assessing skills with an AI simulated team
The experimental setup in Vantage places learners in dynamic, multi-party conversations with AI avatars working together to complete tasks. This setup allows us to control the assessment environment while simulating interactions that are more authentic and representative of real-world scenarios than existing standardized tests. It provides a sandbox to navigate complex interpersonal and situational challenges.
As users interact with AI avatars in open-ended scenarios, such as preparing for a debate or pitching a creative vision, an Executive LLM uses a provided assessment rubric to steer the AI avatars toward an effective assessment. The Executive LLM constantly analyzes the state of the conversation to dynamically introduce specific challenges — such as pushing back on an idea or introducing a conflict — providing the learner with targeted opportunities to demonstrate their skills. As such, it acts as a next-generation adaptive assessment engine, steering the dialogue so that by the end of the conversation, the information needed for assessing the user has been gathered.

Schematic of the LLM-based assessment protocol. As a learner engages in open-ended tasks, an Executive LLM uses a rubric to steer AI avatars and introduce dynamic challenges. This elicits targeted evidence of learner performance, which the AI Evaluator then analyzes for real-time skill scoring and feedback.
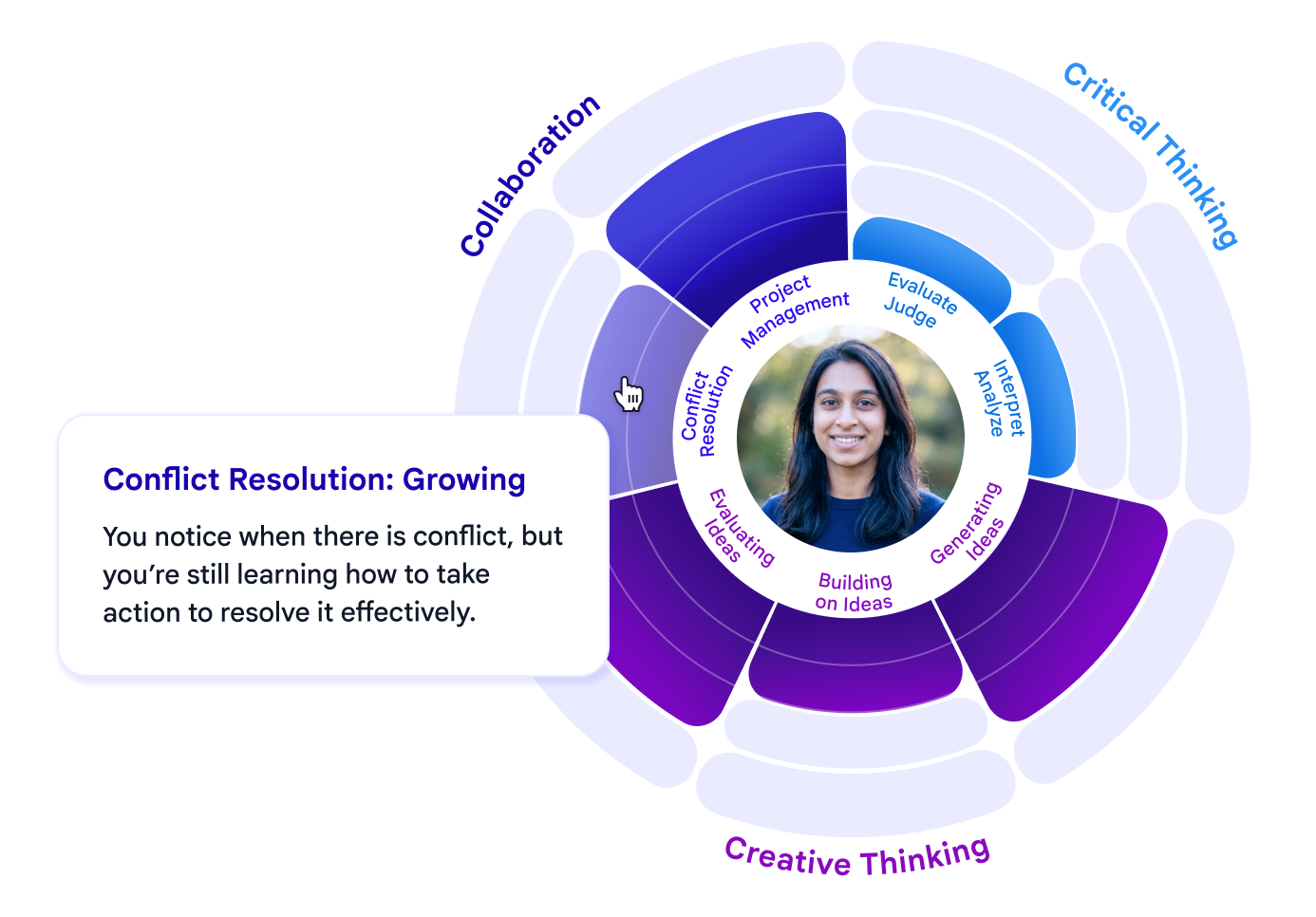
Upon completion of the task, an AI Evaluator analyzes the conversation transcript against the same rigorous assessment rubric used by the Executive LLM to identify and measure specific evidence of skill application. The learner then receives a detailed skill map, consisting of a visual score and qualitative feedback specific to the skills they demonstrated during the conversation. This makes the "invisible" progress of human skill development visible and actionable.

The skill map and feedback example as it’s presented to users including the skills and sub skills currently included in Vantage.
Working with partners to validate how we assess skills
To ensure academic and pedagogical rigor, we established a research partnership with New York University. Together we surveyed common rubrics and aligned them to the tasks in question. The primary focus of this collaboration was to set up and validate the assessment approach. We did this through a joint study with 188 testers ages 18-25 from the US who completed Vantage tasks assessing sample collaboration skills: conflict resolution and project management. We looked at two main research questions:
1. Can we steer a conversation to test specific skills?
A key innovation of Vantage is the use of the Executive LLM to enable adaptive assessment. We evaluated how effectively LLMs could steer a conversation to target a specific skill at a time, such as conflict resolution or project management. We measured the volume of skill-related information demonstrated by the user for that skill, compared to the learner working with AI avatars that are independent and not steered on the same task. Our findings indicated that the Executive LLM does successfully guide the dialogue to produce high-density information and led to significantly more information about the assessed skills while maintaining a natural conversational flow. This capability proved consistent across multiple simulation tasks. Further results and details about the methodology can be found in the technical report.

Rate of information in conversations: The bars represent the fraction of conversations that provided sufficient information for scoring subject skill levels in conflict resolution and project management. Comparisons are shown between the Executive LLM strategy (blue) and independent avatar models (orange), where the responses of the AI avatars are generated independently without coordination. The asterisk (*) denotes a statistically significant difference between strategies.
2. How accurately can LLMs score future-ready skills?
To test the accuracy of the AI Evaluator, we compared its scores against those of New York University raters using the same pedagogical rubrics. The results showed that the agreement between the AI Evaluator and human experts was similar to the agreement between the two expert raters. This suggests that the AI Evaluator’s conversation ratings are comparable to that of human expert raters, establishing Vantage as an effective automated system for skill assessment.

Inter-rater agreement for skill scoring: Comparison of rating agreement between human raters (Human-Human) and between an LLM-based rater and the human raters (Human-LLM). Agreement is calculated using Cohen’s Kappa with quadratic weights, for conflict resolution and project management skills.
We also collaborated with OpenMic, a startup developing AI-powered tools for assessing durable skills. Together we conducted a joint study on creativity and English language arts, to test the AI Evaluator in another context. We analyzed 180 students’ work on creative multimedia tasks, such as character interviews and media articles related to English literature, and compared the AI Evaluator's scores with those of OpenMic's internal experts. Here too, there was a high correlation between the AI Evaluator and human experts, demonstrating the AI Evaluator’s ability to provide valid scoring even on complex, real-world creative tasks.

Creativity scores agreement: LLM rating vs. human expert scores of a complex creativity task. The scores are well aligned with a Pearson’s correlation of 0.88.
Looking ahead towards integration in classrooms
In a school setting, this kind of simulated environment could pave the way for a measurable “skills layer” that sits atop existing school curricula and is integrated into academic tasks. This will enable educators to imagine new forms of assignments, for example, debating a social science topic with the AI avatars or taking on the role of a team lead planning a laboratory experiment. Students could receive feedback on both their understanding of the subject-matter (e.g., the science of the lab experiment) and their skills (e.g., the quality of their collaboration and critical thinking). This approach would be additional to existing group projects with other students, and has the potential to support the development of academic knowledge and durable skills in tandem.

Enabling future-readiness at scale
This research explores how we might transform essential, future-ready, durable skills from hard-to-measure to measurable at scale. By doing so, a more inclusive and accurate representation of future readiness becomes possible. This experiment is a step towards an assessment approach more closely aligned with future needs.
We also hope that our new infrastructure will support further research and efficacy studies across the ecosystem. Researchers will now be able to assess not only the impact of new tools on knowledge retention but also their direct influence on skill development. The potential of such studies is significant, offering a greater understanding of how different pedagogical interventions shape human competencies over time.
Looking ahead, we are expanding our research to tackle the crucial question of transferability — how skills demonstrated in a simulated sandbox translate to real-world human interactions. Furthermore, recognizing that human skills are culturally situated, we will focus on exploring performance across diverse settings to ensure our technology is inclusive and equitable. Beyond assessment, the next phase is to move towards skill growth, deepening our understanding and measuring the efficacy of skill development through practice in simulated environments.
Acknowledgements
Shout out to the Google team members who have contributed to this work: Alon Harris, Alex Moy, Amir Globerson, Anisha Choudhury, Anna Iurchenko, Ayça Cakmakli, Ben Witt, Cathy Cheung, Diana Akrong, Elisabeth Bauer, Hairong Mu, Julia Wilkowski, Lev Borovoi, Lucile Martini, Maya Alva, Nir Kerem, Noa Kerrem Gilo, Preeti Singh, Rajvi Kapadia, Rena Levitt, Roni Rabin, Rotem Yulzary, Shashank Agarwal, Sophie Allweis, Tal Oppenheimer, Taylor Goddu, Tracey Lee-Joe, Tzvika Stein, Yaniv Carmel, Yishay Mor, Yoav Bar Sinai, and Yuri Lev. Thanks to our New York University collaborator Yoav Bergner and his team, and to our partners from OpenMic: Aviad Segal, Eliad Carmi, Hadas Gelbart, and Yael Bar Moshe. We are grateful for the insights from Cristine Legare at The University of Texas at Austin, and J.D. LaRock, the President and CEO of the Network for Teaching Entrepreneurship (NFTE). Special thanks to our executive champions: Niv Efron, Avinatan Hassidim, Amy Keeling, Katherine Chou, Yossi Matias, Ronit Levavi Morad, Chris Phillips and Ben Gomes.
Quick links
Other posts of interest
-

June 24, 2026
Thinking to recall: How reasoning unlocks parametric knowledge in LLMs- Generative AI ·
- Machine Intelligence ·
- Natural Language Processing
-

June 3, 2026
The next chapter in flood resilience: Open sourcing Google’s hydrology framework- Climate & Sustainability ·
- Earth AI ·
- Generative AI ·
- Open Source Models & Datasets
-

May 28, 2026
A New Era of Discovery: Google Research at I/O 2026- General Science ·
- Generative AI ·
- Global ·
- Quantum